
RAG, or Retrieval-Augmented Generation, is a technique that combines the strengths of two AI models: a retrieval system and a generative model. It works by first retrieving relevant information from a knowledge base (like a database or collection of documents) based on a user's query. This retrieved information is then fed to a generative model – like a large language model – which uses it to create a more accurate and contextually relevant response. Essentially, RAG enhances a language model’s knowledge and reasoning capabilities by supplementing it with retrieved external data.
RAG pipelines are particularly useful in applications where access to up-to-date or domain-specific knowledge is crucial. By dynamically fetching relevant information instead of relying solely on the LLM’s pre-trained knowledge, RAG-based systems can provide more precise, context-aware answers, making them ideal for chatbots, research tools, and enterprise AI applications.
Here we will show you the basics of how to setup RAG with OpenWeb UI.
Prerequisites
When it comes, for example, to your own company knowledge database, you really should opt for a local installation. We showed you how to do this in our last article.
After all, you don't want to pass on your trade secrets to third parties. And having your domain knowlege accessable via an AI chatbot has it advantages over a classical wiki: natural language processing. The user does not necessary needs to to have specific keywords, for example, in mind.
Setup RAG with OpenWeb UI
Now that we have successfully built our LLM service, we can define our RAG with the desired model and documents. To do this, we need to create a so-called “Knowledge”, a collection of documents that will serve as the foundation for our RAG system. Next, we create a model that generates responses based on this Knowledge. Finally, we can use this model to process queries. That’s it! So in detail:
The Knowlege Base
In Open WebUI, go to Workspace and in Knowledge tab, hit (+) button to create a new Knowledge:
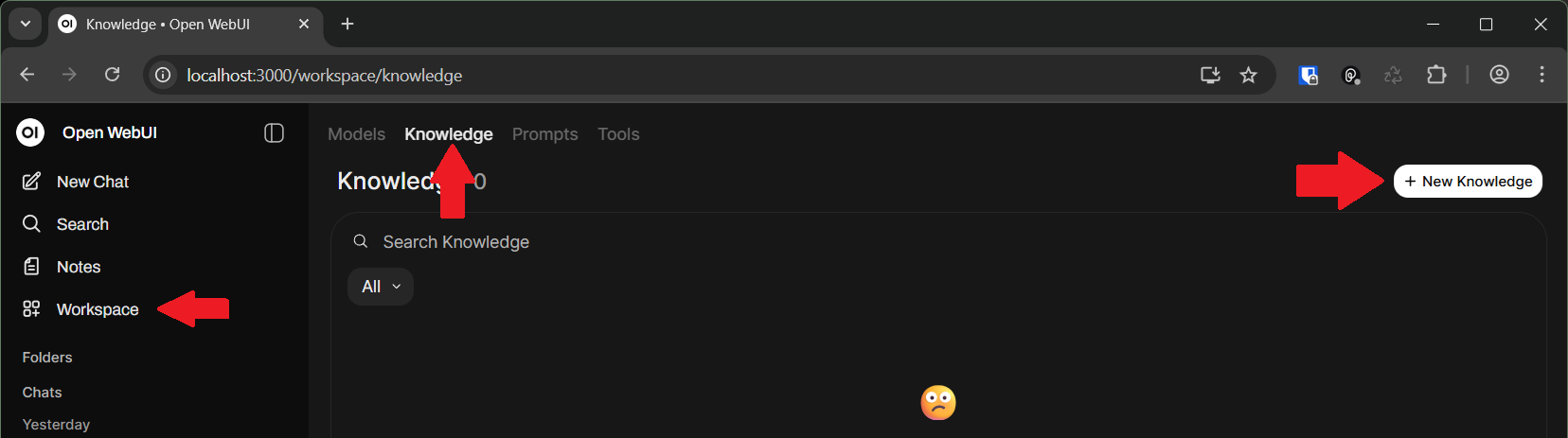
Enter the name and description and Create Knowledge.
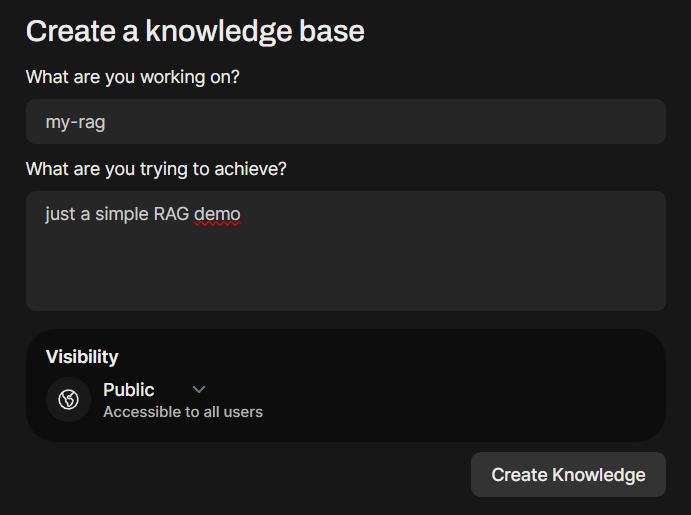
Now, click on the newly-created Knowledge and add your desired documents using (+) button and upload your files. For demo purposes we add 3 PDF files containing this content:
File1:
Hello, my name is Alex.
I work for Google and I get 130000 $ a year.
I like sushi.
File2:
Hello, my name is John.
I work for OpenAI and I get 150000 $ a year.
My favorite dish is pizza.
File3:
Hello, my name is Rick.
I work for Microsoft and I earn 115000 $ a year.
I like burgers.
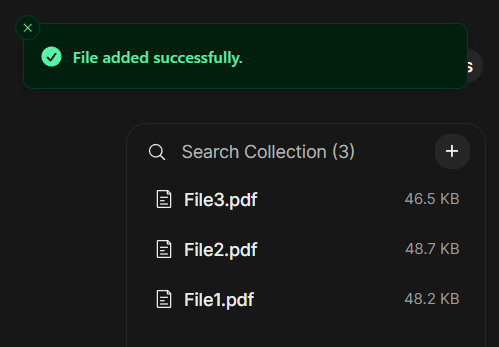
Now, you have successfully added two files to your Knowledge. You can always add or delete files, but pay attention if contents of a file changes, you need to delete the former file from the Knowledge and upload it again or re-sync the whole Knowledge.
Hint
In Settings/Admin/Documents of Open WebUI you can define some parameters for text extraction from your documents. Please keep in mind that "extract images" in PDF files only does a basic OCR text extraction from images. This means: when you have, for example, an Org Chart of your company in one of those PDF files, only the names of the sub-orgas will be extracted but not their releations to each other!
Define the Model
In Workspace go to models tab, hit (+) button to add a new model. Enter the model name, Select Base Model on which you want to create your RAG. Then in select knowledge, add your already-created Knowledge to this model. Finally, you have something like this (we named our knowlege-aware model here simply "my-rag"):
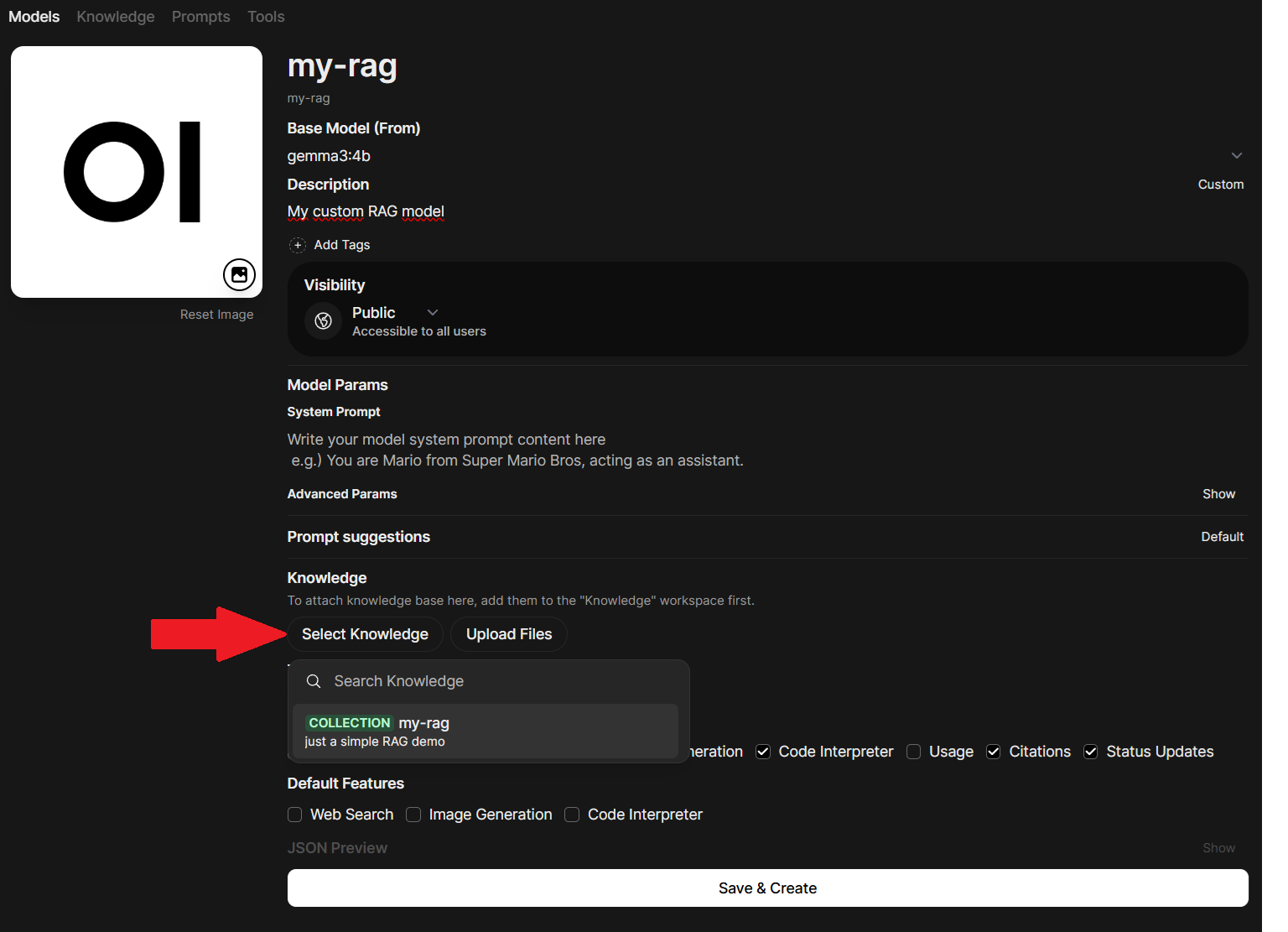
press Save & create and you have this model in models list now.
Finetuning
Now that we have built our RAG, we need to improve the efficiency of the pipeline. There are multiple parameters that should be tuned in a RAG pipeline to optimize the model’s performance.
When go head back to Workspace and click on the my-rag model you can expand the Advanced Parameters section in order to tune parameters like f.e. the temperature:
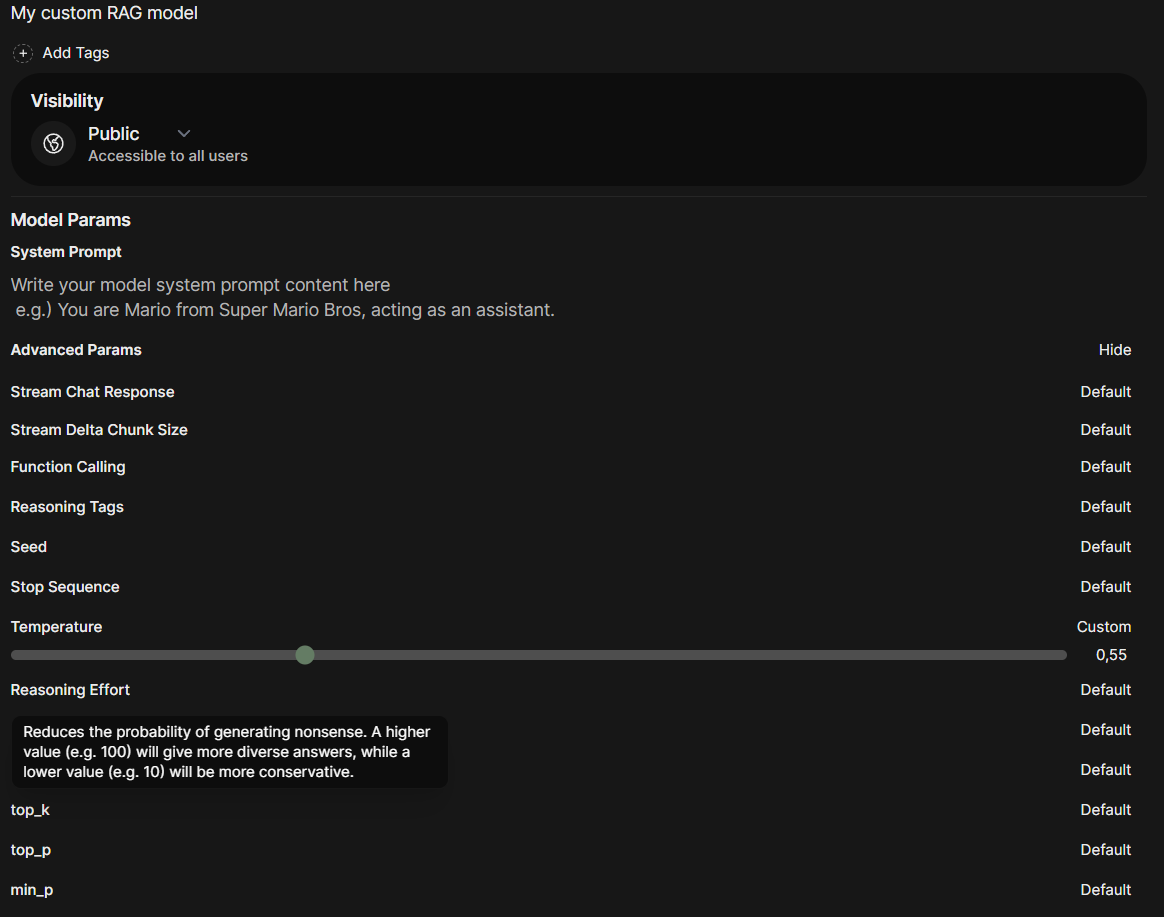
Max Tokens (num_predict) sets the maximum number of tokens the model can generate in its response. Increasing this limit allows the model to provide longer answers, but it may also increase the likelihood of unhelpful or irrelevant content being generated. (Default: 128)
In Open WebUi, under Settings>Admin Settings>Documents you can also set a lot of general parameters for RAG like for example:
Top K: Number of relevant documents to be retrieved.
Chunk Size and Chunk Overlap: You may have long documents which needs to be separated in order to be easier searched.
Smaller chunks work better for precise factual retrieval while larger chunks preserve more context for complex topics. Technical documentation benefits from smaller chunks and higher Top K values. Narrative content works better with larger chunks and more overlap.
RAG Template: Query by which you ask model to finds the relevant documents and retrieve the answer. You can consider additional tips to answer in the template.
### Task:
Respond to the user query using the provided context, incorporating inline citations in the format [source_id] **only when the <source_id> tag is explicitly provided** in the context.
### Guidelines:
- If you don't know the answer, clearly state that.
- If uncertain, ask the user for clarification.
- Respond in the same language as the user's query.
- If the context is unreadable or of poor quality, inform the user and provide the best possible answer.
- If the answer isn't present in the context but you possess the knowledge, explain this to the user and provide the answer using your own understanding.
- **Only include inline citations using [source_id] when a <source_id> tag is explicitly provided in the context.**
- Do not cite if the <source_id> tag is not provided in the context.
- Do not use XML tags in your response.
- Ensure citations are concise and directly related to the information provided.
### Example of Citation:
If the user asks about a specific topic and the information is found in "whitepaper.pdf" with a provided <source_id>, the response should include the citation like so:
* "According to the study, the proposed method increases efficiency by 20% [whitepaper.pdf]."
If no <source_id> is present, the response should omit the citation.
### Output:
Provide a clear and direct response to the user's query, including inline citations in the format [source_id] only when the <source_id> tag is present in the context.
<context>
{{CONTEXT}}
</context>
<user_query>
{{QUERY}}
</user_query>
Real World Settings
In order to work in a meaningful way with RAG in Open WebUI, you should consider raising some values in the Admin Panel / Documents section:
- Chunk Size = 2000
- Chunk Overlap = 200
- Top K = 20
- Top K Reranker = 10
- Embedding Model = BAI/bge-reranker-v2-m3
The default local embedding model is sentence-transformers/all-MiniLM-L6-v2. This model is outperformed by BAAI/bge-reranker-v2-m3 in any way. Just type in the model name (or copy/paste it), hit the download icon and start a re-index (found on the bottom of the page).

Conclusion
You’ve now built a powerful RAG-powered LLM service locally using Ollama and Open WebUI. With this setup, you can use retrieval-augmented generation to create intelligent, context-aware applications. Whether you’re developing chatbots, research tools, or enterprise AI solutions, this pipeline provides a strong foundation for delivering accurate and insightful responses.
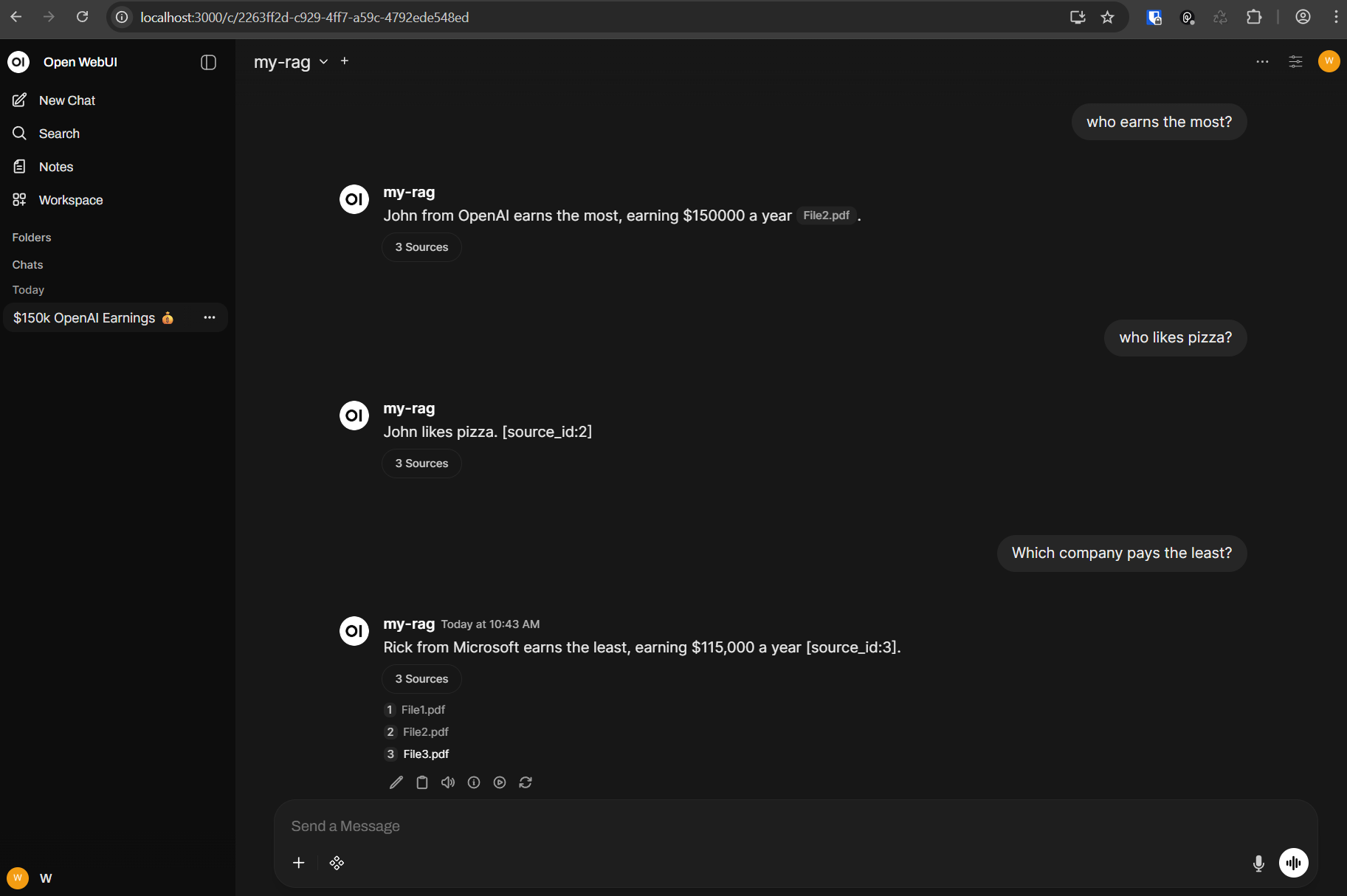
Remark: When users work with the standard Open WebUI interface, a small potential risk becomes apparent: if the user selects the wrong model from the list of models, the incorrect model will naturally be unable to perform RAG tasks. In this case, it would be advantageous to offer a proprietary chatbot within the company that explicitly uses the appropriate RAG model. See here how to create a WebAPI with .NET that communicates with Open WebUI.
See also